The four layers of interoperability in the European Interoperability Framework (EIF3, 2018)—legal, organizational, semantic, and technical—have been instrumental as a guiding mechanism. It highlighted that interoperability is multi-faceted: it cannot be solved by software engineers alone. No, it is to be solved in an integrated way, solving legal concerns with a legal team, solving organisational aspects using managers, solving technical hurdles with software engineers and making sure everyone has the same understanding for the terms used. It introduced a new level of abstraction on top of how public administrations (who are the main target of the EIF) would look at making services run across the border of their own organization. Interoperability becomes a governance concern you need to think about in advance instead of in hindsight.
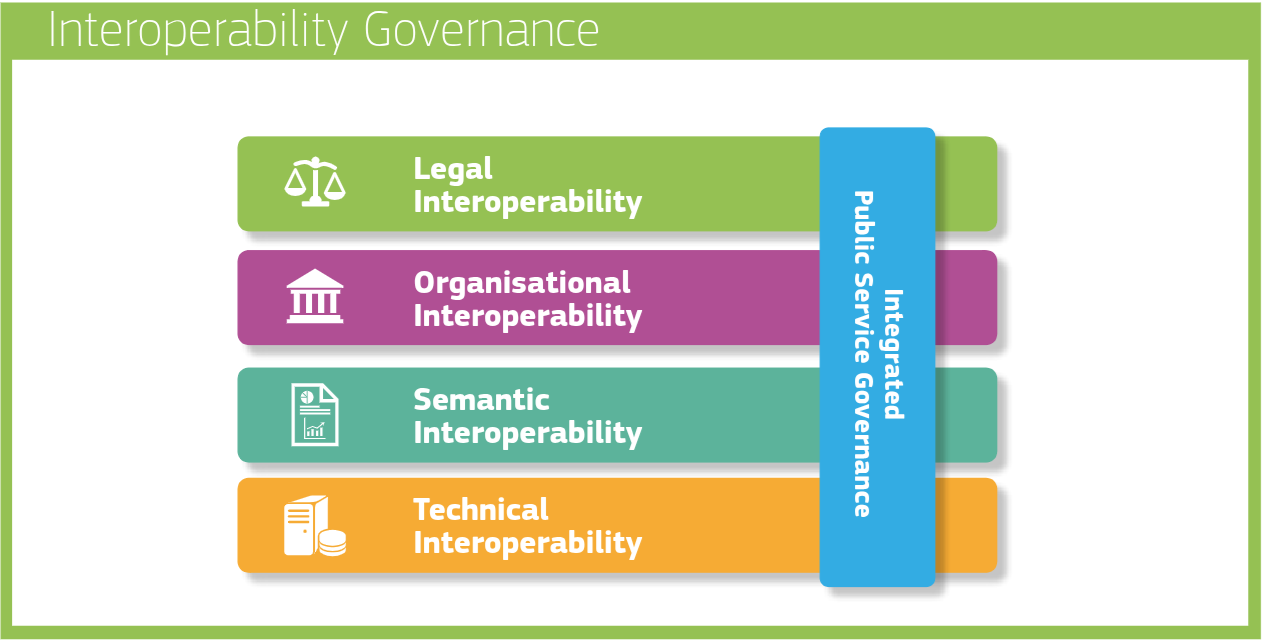
Today this kind of layering has become well-understood. However, not all interoperability challenges are now solved as we’re still taking the first steps into automating integrations, so they are cost-effective, reliable and scalable. Next to these 4 layers, it’s time to take the next step in the complexities of interoperability governance and look at where we are today, where we should be heading tomorrow, and what our ambition will be in the long term.
A simple example of where we are today is the General Bikeshare Feed Specification (GBFS). GBFS is a set of JSON schemas that makes it easier to discover and use shared mobility modes. It is undeniable that this specification has had a positive effect on interoperability for apps to integrate the availability of shared mobility in a region. However, the use cases on which interoperability was created remain limited to exactly those clients that specifically coded against the GBFS schemas. There’s no reuse of semantics or specific interaction patterns that would help non-GBFS clients to still perform a task on the data, for example, to show it on a map, or to study the data as time series, or to show opening hours of specific services.
For that kind of cross-application reuse to become possible, we need to raise our ambitions. Instead of each ecosystem inventing its own schema and API, we need a way to separate concerns more clearly: vocabularies that define shared terms, application profiles that define how those terms are used in a context, and interaction patterns that describe the workflows or exchanges between systems. Add to that global identifiers that work across domains, and you get the foundation for reuse. This is where interoperability stops being about “connecting system A to system B” and becomes about building common building blocks that any system can adopt.
One separation we know well in the world of Linked Data is between vocabularies and application profiles.
Vocabularies provide the global identifiers for domain specific terms.
Application profiles, on the other hand, assemble these terms from one or more vocabularies into a schema that a particular system or service expects.
For example, an application can use the property geo:asWKT from the OGC GeoSPARQL vocabulary to indicate that something has geospatial coordinates.
This pattern can then be reused by many other systems, even if they are working in different domains.
Not everyone will choose the same property to describe geospatial data, but that’s where alignments come in.
The global identifiers can be reused to provide a mapping between patterns.
A publication, that so far did not receive the attention it deserves, elaborating on this exact challenge, is “A Web API ecosystem through feature-based reuse” by prof. Michel Dumontier (known from his work on the FAIR principles) and prof. Ruben Verborgh. APIs were originally intended to make automated connections easier, but in practice they often add complexity. Each new API introduces its own contract, forcing developers to write a dedicated client, which leads to one client per API. The paper argues for a shift to feature-based reuse: instead of treating every API as a silo, describe the features it provides and reuse features that others have already documented. This way, a client only needs to implement a set of reusable features once, and it will work across multiple APIs. It creates a looser, more flexible contract between APIs and clients, which is far more scalable than today’s approach.
Think of common API features such as pagination, filtering, synchronisation, or contract negotiation. Instead of every ecosystem inventing its own way of doing these, we can standardise the patterns once and reuse them everywhere. For example, the TREE hypermedia specification provides a reusable interaction pattern for pagination and subset discovery. The SEMIC Linked Data Event Streams (LDES) specification builds on that to describe how a client can stay in sync with a changing dataset. For contract negotiation, there is the Dataspace protocol that defines the interaction patterns as a state machine. These are concrete, reusable building blocks that any domain can adopt, whether you’re in the domain of cultural heritage, traffic measurements, or building public services. Domain specifications will this way become smaller, and be a combination of reusable components rather than a reinvention of the same patterns.
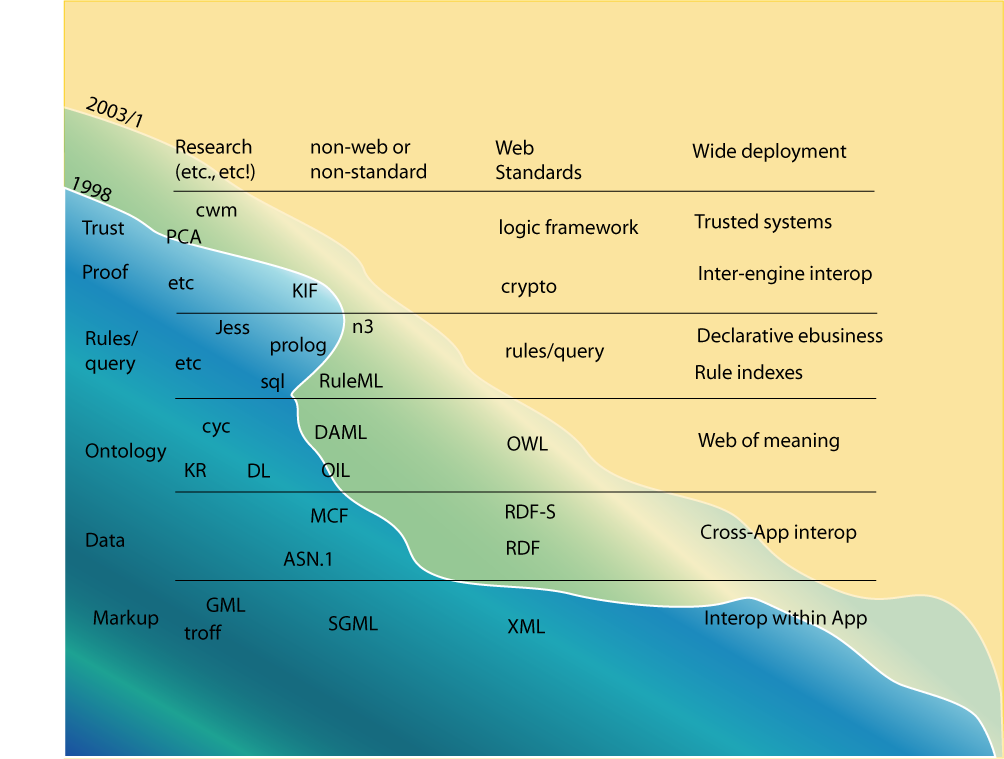
In a 2003 presentation, prof. Tim Berners-Lee pitched the “Semantic Web Wave” (see above). The idea was that there is a gradual approach to interoperability, where systems that already put in the effort to have interoperability within an ecosystem through tightly coupled specifications (interoperability within an app ecosystem), can evolve towards reusing Linked Data vocabularies and RDF serializations (cross-app interoperability). Once they do, they can take the next step: documenting and sharing the logic so machines can interpret the data across implementations. This last step goes beyond cross-app interoperability by insinuating that we won’t need to build any domain specific software anymore. We will be able to ship a domain agnostic engine, together with the data. The engine will be able to, through procedures and logical rules described in the data, understand how to interact with various systems for you.
The three ambition levels for interoperability
All good things come in threes. Whenever positioning conceptual levels, I believe it is to convey where we are today, what we need to reach for in the short term and what the heading is in the long term. Level 1 is what is already being adopted, level 2 is what is within reach, but often not yet available off the shelf, and level 3 should be a future outlook we can prepare for today. Also the Semantic Web Wave by Tim Berners-Lee grasped the idea that you start with systems that only work within one tightly coupled ecosystem, then move towards shared vocabularies and patterns for interoperability cross ecosystems, and finally, you reach a point where systems can even share the logic for interpreting the data. Let’s reiterate and modernise those levels for today’s use cases.
The three levels I propose follow the same idea and naming:
Level 1 — Interoperability within an app ecosystem
This is where most initiatives start. A group of actors in the same domain agrees on a format and a protocol. Developers can read the spec, build their implementation, and everything works smoothly — as long as you stay inside that ecosystem.
Think of the General Bikeshare Feed Specification (GBFS) for bike-sharing data, GeoJSON for geospatial points, MARC 21 in libraries, HL7 in healthcare, or NeTEx in public transport. Each technology has an undeniable impact within its own ecosystem, but if you want to use that data in another domain or platform, you’ll need to write extra code to bridge the gap.
Level 2 — Cross-ecosystem interoperability
Here, you go beyond your own domain and design with reuse in mind. Identifiers are global rather than local. Vocabularies, application profiles, and interaction patterns are separated so they can be mixed and matched. This makes it possible for cultural heritage data to be aggregated with the same interaction patterns as a transport API, or for healthcare systems to reuse the same contract negotiation protocol as an industrial dataspace. It’s where RDF, SHACL, and hypermedia APIs start to appear as they make this kind of reuse possible.
Level 3 — Inter-engine interoperability
The final step is when you also include the logic in your specifications, so a machine can interpret, verify and interact with your data and systems without being built for your specific domain. This is where AI and rule engines meet.
Today, most projects stop at Level 1 because it’s faster to implement and delivers value quickly. Working our way upwards, we need to be able to show evidence that indeed, by making the abstractions necessary for Level 2 and even Level 3, will save a lot of work later.

P.S.
Are you interested in learning about interoperable dataspaces technology? At this moment the registrations are open for the course on Linked Data, Solid and interoperable dataspaces. The course starts in September and runs until January.
Thank you Jos De Roo for telling me about this initial vision of Tim Berners-Lee at the coffee machine. I decided to adopt these original terms for interoperability ambitions as coined by him.
I am at this moment part of the expert team on the European Interoperability Framework (EIF). In this context I’m planning a couple of blog posts, for which this one is the first. These posts however do not reflect the position of the EIF.