Jekyll2025-09-09T06:32:23+00:00https://pietercolpaert.be/feed.xmlPieter ColpaertProfessor public Web APIs and Linked DataPieter ColpaertSEMANTiCS2025 Trip report2025-09-08T00:00:00+00:002025-09-08T00:00:00+00:00https://pietercolpaert.be/conferences/2025/09/08/semantics-trip-report
SEMANTiCS is an international conference that brings together companies and research working on technologies that aim to be interoperable through semantics.
In 2025, we visited the conference with a bunch of colleagues, as well as with the companies from the DiSHACLed project.
As I wasn’t able to get my family logistics in the first week of school sorted out in such a way I would be able to attend the whole of SEMANTiCS2025, I attended the first day online.
It’s great about hybrid conferences nowadays that it gives you these options. This way I also had both experiences of the hybrid conference.
The keynote of Hannah Bast
The keynote of Hannah Bast was as thought-provoking as impressive.
At the start of my PhD on linked transport data her publications on route planning were instrumental for my own research.
Today she’s shaking up the world of triple stores with her work on the QLever SPARQL engine that is able to beat the state of the art on many fronts for querying truly big knowledge graphs such as OpenStreetMap, Uniprot, Pubchem or Wikidata.
During the keynote she was very down to earth about benchmarks: although QLever scored pretty well according to their own tests on these benchmarks, they are still working on yet another SPARQL benchmark to have a more honest comparison. The work on SPARQLoscope is to be presented at ISWC2025 later this year.
A line during the keynote that certain stuck was: “professors don’t code”.
This was given as a reason why academic software is often of low quality: students have to learn the coding part by themselves.
Hannah Bast herself is certainly an exception to this statement.
I personally did not have the impression that “professors don’t code” within our field, certainly as I had her as an example during my PhD.
Also my own supervisor at the time, Ruben Verborgh, I often found deep-down in coding projects.
Nevertheless, I do not think my own strenghts can be found in my coding qualities.
I do write code, but that’s more incidental—like peeling potatoes when you want to make fries.
While I have tried to position decent software in the past, my focus today is on building interoperable dataspace ecosystems through specifications (see previous blog post).
Luckily in our Knowledge on Web-Scale team we have multiple professors, each with a different set of qualities.
I would have liked to talk this over with Hannah Bast over a coffee break, but wasn’t able to talk to her before she had to leave—that will have to happen on a next occasion.
Our team in an organizing role
Our team took on quite some responsibilities for organizing workshops and tutorials:
It’s certain that the world of Linked Data needs better developer tooling. Ruben Taelman, Jerven Bolleman and Jindřich Mynarz co-organized the Developer Workshop.
A note to self: if you let your PhD students organize a tutorial at a conference, the tooling they are organizing this tutorial for is all of a sudden going to be pollished. Ieben Smessaert and Arthur Vercruysse organized the RDF-Connect tutorial for building data pipelines across environments. You can still do the tutorial yourself at home and ask them for feedback. The tutorial is going to extended as a full-day tutorial at the ISWC2025 conference.
The Semantics for Transport workshop was organized by a new organization committee this year. I hope it’s the start of renewed interest in the topic!
The NXDG workshop on next generation data governance, about technologies like the Data Privacy Vocabulary (DPV) and the Open Digital Rights Language (ODRL) organized by Harshvardhan Pandit and Beatriz Esteves.
A fishbowl session on dataspaces and whether semantics still play a role
I brought an opening statement in the fishbowl in which I referred to the Eclipse dataspace protocol.
This specification uses JSON-LD, ODRL and DCAT.
How can anyone claim that semantics would not be of interest to dataspaces? They use our work!
What remains however is that, on the data plane (the ODRL and DCAT is in the “control plane”, to set up the data connection), we still have to fight the same fight.
If we want interoperable instance data, we will still need to bring semantics to the individual domains.
That’s not a characteristic of dataspaces specifically, but of working with data in general.
We have a Flemish funded project going on called DiSHACLed. For that project we’re working on (i) extending DCAT with SHACL shapes for discovy algorithms in data portals, (ii) on SHACL based data pipelines with RDF-Connect, (iii) on extending SHACL with UI features (Ieben from our team is following the W3C data shapes working group for that reason), and (iv) looking at business models for dataspace actors.
We’re doing this with Inuits’ Elody team, RedPencil and Sirus: three high-potential companies in the world of semantics and interoperable data services.
The dishacled team at semantics
RedPencil is well-known within the SEMANTiCS community already.
For Elody, it was a first time encounter.
We had a lunch together to discuss the conference and discuss how to approach certain tasks within the project differently now.
Jelly and nanopublications
Probably the biggest aha-erlebnis I got during the conference was with Jelly of my namesake Piotr Sowiński.
He had a presentation in which he showed the great speed ups (proceedings yet to be published...) of implementing this within nanopubs.
During a coffee break I expressed my skepticism that it is really the binary format that did the trick.
However I was shown to be wrong: with the help of an LLM I coded up a Python script (I’m not a python developer, and Jelly doesn’t have NodeJS support at this moment), that clearly showed an impressive increase in throughput.
The test is a bit simplistic, but even if you would add the complexity, the increase will remain substantial.
Let’s make sure Linked Data Event Streams can work with Jelly.
Next year, we’ll be the local host of SEMANTiCS and hope to welcome you all in Ghent!
Notes to self for organizing next year:
Make sure people’s names are on both sides of the name tag
Make sure the proceedings are available before the conference: not being able to go through the paper while attending talks breaks how some people, including myself, try to attend talks efficiently
Try to get a brass band during the conference dinner (Thanks Jean-Marc Acke for the suggestion)
]]>Pieter ColpaertFour types of specification artefacts2025-09-03T00:00:00+00:002025-09-03T00:00:00+00:00https://pietercolpaert.be/interoperability/2025/09/03/four-types-specification-artefacts
Interoperability isn’t about creating the one standard to rule them all.
It’s about creating small reusable pieces of the puzzle.
In the world of Linked Data we go in the right direction, but don’t go far enough, which still today leads to poor adoption despite containing the right ideas.
I argue we need four types of reusable artefacts in specification:
vocabularies, application profiles, interaction patterns, and implementation guides.
Together, they form a toolbox for connecting systems across domains:
implementation guides provide the much-needed answers developers need to build their systems, while interaction patterns provide composable functionality on top of the application profiles.
Allow me to elaborate…
It’s not a secret that I’m a big fan of the approach Linked Data is taking when it comes to interoperability.
The technology is based—as the name implies—around the idea of being able to link to each others’ concepts using global web identifiers, or simply web addresses (IRIs).
For the domain models, this already means a split in types of specifications into vocabularies and application profiles.
Application profiles are well-defined “schemas” that tell data providers what the shape is their data needs to adhere to.
Yet, it’s the vocabularies that make the terms used in these profiles reusable in others, as various schemas can reference the same concepts, and those concepts in turn can be interlinked again in case a project would like to align in a later phase.
It’s this kind of separation in types of specifications or artefacts of a consensus that made me wonder whether other types of specs should exist.
Outside of the Linked Data world I often see specifications that try to cover everything by defining APIs and schemas in one go.
This way, they skip the reuse of existing terms and patterns.
However, Linked Data specifications often don’t cover enough.
For example, if you want to build a metadata catalog, there is a W3C standard for that: the DCAT vocabulary.
The European application profile—SEMIC’s DCAT-AP—then defines what EU organizations must support in order to work within aggregators.
However, when you now would like to do something with a data portal, all options are left open.
E.g., how do you take a copy of the data portal and stay in sync with it? What is the procedure to add a new dataset in the portal?
There is no answer to be found in neither the DCAT vocabury or the European application profile.
I was part of a SEMIC pilot on the question “how do I take a copy of a DCAT-compliant data catalog and stay in sync with it afterwards”.
We had been working on a specification for an interaction pattern between clients and servers for replication and synchronization and thought we could apply it exactly to this domain.
However, it remains quite abstract how to build this specifically for data catalogs.
For that purpose, we’ve built an implementation guide called DCAT-AP Feeds in collaboration with DIGG, the digitization agency in Sweden.
The implementation guide reuses the application profiles for DCAT-AP, as well as the Linked Data Event Streams interaction patterns for staying synchronized with event streams.
While it did not add a lot of normative text, it brings all of this together in a specification that is ready to be implemented for aggregating data catalogs across Europe.
How we approached DCAT-AP Feeds is also how I see this happening in other specifications.
When these interaction patterns become composable into implementation guides, that’s when we’re going to see interesting reuse happen.
Let’s go through the 4 types of specifications, and I’ll show what I think are good examples of this composability.
1. Vocabularies – agreeing on words
Vocabularies are simply lists of web addresses with a certain meaning one can use.
Their meaning is explained in full text.
The DCAT vocabulary for example contains definitions for terms like Dataset, Catalog or DataService.
You can decide whether you agree with the definition and reuse the term, or you can decide to be more specific, and instead create your own vocabulary.
Vocabularies can contain classes and properties for a domain model you may want to instantiate, but equally as well it can contain code lists or a taxonomy.
In more advanced projects, also complex relations between terms can be described in something we would start calling an ontology.
It’s hardly possible to “comply” to a vocabulary, while this is of course something you would expect from a standard.
You can reuse terms—or link up to terms—and this way make sure semantic interoperability problems will take less effort to solve.
However, it is clear that this is only a first step towards solving interoperability.
We will need more tools than just vocabularies…
Technologies
RDFS (RDF Schema—although I wouldn’t call this a schema anymore today) to describe classes and properties,
SKOS (The Simple Knowledge Organization System) to describe code lists and taxonomies,
OWL (The Web Ontology Language) to describe more complex relations between terms.
As these are quite established RDF technologies, Large Language Models are particularly good at helping you to create those. Check out this example using Mistral.ai (prompt: “I’m creating an RDF vocabulary for father, mother, person, kid and the relations between them. Generate a turtle code example using RDFS.”).
Example: governmental vocabulary initiatives in Europe
In Europe, it is common to maintain vocabularies at different levels: regional, national, and European.
Each of these initiatives publishes terms that can be reused across projects, lowering the cost of integration.
At the European level, SEMIC maintains the so-called Core Vocabularies such as the Core Person Vocabulary and the Core Location Vocabulary.
These are used in many application profiles, ensuring that a “person” or “address” is described in the same way across member states.
In Flanders, we have the Open Standards for Linking Organizations (OSLO) initiative.
OSLO publishes RDF vocabularies for concepts such as addresses, mobility, culture and many others, which are then applied in local data exchanges and reused by cities and regions.
The OSLO-initiative is not in contradication with the European vocabularies: it reuses IRIs where there’s a perfect match, and it links up to broader terms where relevant.
Other countries have similar efforts, such as Finland that maintains its own reusable vocabularies at finto.fi.
I believe every country should have an entrypoint to their vocabularies like this.
Example: ActivityStreams
ActivityStreams is a vocabulary originally developed at the W3C to describe social web activities.
It defines concepts such as “Person”, “Note”, “Like”, and “Follow”; but also more generic concepts such as a “Create”, “Update” and “Delete”.
This vocabulary is reused in the ActivityPub protocol, which powers federated social networks like Mastodon.
Thanks to the vocabulary, a “Like” expressed in one system can be understood in another, even if the systems themselves were not built together.
In the DCAT-AP Feeds implementation guide, we also re-use the semantics of a “Create”, “Update” and “Delete” from this vocabulary.
It’s a great illustration of how vocabularies allow reuse across completely different applications.
2. Application profiles – agreeing on shapes
We’ve established that a vocabulary alone is not enough.
You also need to specify what shape of data an application actually expects.
While RDF vocabularies have been around since the late nineties already, application profiles are a more recent development.
They gained traction when it became clear that applications also need to agree on which terms are required, which are optional, and how they fit together.
Profiles make these expectations explicit so that producers and consumers know exactly what to exchange, and this can be validated.
It is thus possible to comply to an application profile, yet this is still to be taken with a pinch of salt:
what group of statements you decide to validate at which phase during a process is also important, yet this is not typically part of an application profile. For that, we will have to refer to the next section.
Technologies
SHACL (the Shapes Constraints Language) describes shapes for RDF graphs and is widely used in European application profiles.
ShEx is an alternative shape language with a more compact syntax. I haven’t personally used it, but have encountered it in health care use cases.
Both technologies are being discussed in the free online book “Validating RDF”.
In Flanders, the vocabularies initiative also comes with application profiles, and SHACL artefacts, that guide local governments in publishing interoperable datasets.
Other countries host national schema catalogs. In France, schema.data.gouv.fr serves as a central registry for public-sector data schemas, allowing producers to discover, document, and align their data models to commonly used formats.
Similarly, Italy and other EU member states have their own initiatives to document and publish application-specific schemas, supporting interoperability at the national level.
Also non-Linked Data schemas can be found there that structure CSV-files or validate JSON structures with JSON Schemas.
While these initiatives have their merit, I believe we should be unambiguous about whether certain terms follow the same semantics or not.
The decoupling of application profiles and vocabularies is an important one.
Example: the dataspace protocol
In the world of dataspaces, the Dataspace Protocol relies on JSON-LD combined with JSON Schema validation to ensure that contracts and dataset descriptions can be interpreted consistently across participants.
This is a very pragmatic approach to bridge the gap between interoperability within an app ecosystem and cross-app interoperability.
Instead of SHACL or ShEx, a serialization specific validation method is used.
The drawback is that the protocol is now unnecessarily coupled to JSON, and that it also standardizes the structure of the JSON document instead of the shape of the graph.
The benefit is that this looks very familiar to developers who have worked on client-server implementations in the past.
All in all, these are just implementation choices that reach a similar goal.
Example: The European Union Agency for Railways (ERA)
In the railway sector, ERA has published SHACL shapes that specify how railway entities such as stations and tracks must be described.
National railway companies may have richer internal models, but when they want to interoperate at the European level, these shapes define the minimum requirements.
This way, a European Railway Infrastructure (RINF) Knowledge Graph can be created, which today is a fundamental tool for the railway sector to understand what vehicles will be compatible with a certain railway route across the borders of EU member states.
3. Interaction patterns – agreeing on flows
Interoperability is not just about validating data or reusing vocabulary terms, but also about how systems or agents interact with each other.
These interactions can be low-level, such as how to exchange messages over HTTP, or high-level, such as describing organizational procedures.
A story without technology I like to tell is how you change your first name.
You cannot take your identity card, scratch the name and replace it with another using a permanent marker.
Instead, you need to follow an official procedure, usually defined by your municipality.
For example, here is the information page from Brussels documenting the steps you need to take.
Once you’ve completed the process, you are issued a new identity card, and other systems—such as the population register—are updated as well.
Not the right way to change your name, yet this is often how we implement our web services today.
On the Web we often forget this procedural layer.
We simply overwrite data, re-upload a dump, or push an updated knowledge graph, without any guarantee that the right process was followed.
By making interaction patterns explicit, we can attach trust and compliance levels: when a system proves that a certain procedure was followed, consumers can rely on it.
Interaction patterns are reusable flows, comparable to state machine or flowcharts, to achieve a certain goal.
They define not only the messages exchanged, but also the order in which they happen and the conditions under which they succeed.
In order to do so, they can reuse terms from vocabularies and can define the shape of the data they expect in application profiles.
We can already see them in action across domains, from liking someone’s post on social media, to data synchronization, to contract negotiation in dataspaces.
Such patterns should be composable: I might want to synchronize a dataset, but also tell someone I “liked” the dataset it after I negotiated access to the dataset.
Technologies
Developer documentation explaining in a higher level fashion how the process works using state machines, flowcharts or sequence diagrams, or lower-level documentation such as HTTP protocol bindings,
Hypermedia controls to describe the next possible steps in an interaction,
Rule languages, such as Notation3 or datalog, to formalize and automate such state transitions,
Procedure extensions to CPSV-AP or other workflow notations for higher-level organizational processes.
While the previous chapters already have established tooling within and outside of the linked data domain, convergence on technologies to achieve interaction patterns is still on-going.
The majority of specs that I find good examples of interaction patterns today are written as developer documentation.
Developer (or LLM?) documentation means that still those patterns will be hard-coded.
It would be nice if we could build an abstraction for those patterns, so that engines can automatically understand the interaction pattern and do not need to have their code adapted (this is what I called ambition level 3: cross-engine interoperability in my previous post).
There is however no consensus yet on this abstraction layer, and I also doubt whether there will ever be one definitive one.
The idea of hypermedia controls in APIs have not really reached the adoption one would have imagined, as they were positioned as part of one of the constraints in the REST architectural style by Fielding in the early 2000s.
However, I still believe this is the way to go: when fetching a page, you should also get the descriptions—so-called hypermedia controls—of where you can go from here.
Various Linked Data initiatives adopted this idea.
E.g., the Linked Data Platform (LDP) is a vocabulary, application profile and set of interaction patterns with HTTP protocol bindings for read-write Linked Data information resources.
When you implement these interaction patterns, a client will be able to understand how to read the contents of elements in a possibly paginated container, and how to change their representations.
LDP is then again adopted by the Solid project for building personal data vaults, that takes a subset of the interaction patterns within LDP, and extends it with access control and user profiles (WebID).
Other specifications like Hydra, TREE, Web of Things, or ActivityStreams collections also adopted hypermedia at the heart of their interaction patterns.
CPSV-AP is an application profile to describe public services in Europe.
It would be nice if CPSV-AP would be extended to also contain a description of the procedures that are otherwise just described in full text (cfr. the information age to change your first name).
This was an experiment already back in 2021 in Flanders with OSLO-steps.
Example: ActivityPub
In ActivityPub, the protocol behind Mastodon, interaction patterns are at the core.
When you “like” a post, there’s a defined flow: your server creates a “Like” activity, delivers it to the author’s server, and that server then updates its counters.
The same goes for following someone, posting, or resharing content.
These flows are reusable: any implementation that supports the ActivityPub protocol understands what a “Like” or “Follow” means, even if it was initially published in entirely different communities.
Example: synchronization with LDES
Another example is Linked Data Event Streams (LDES).
Here, the interaction pattern defines how clients can replicate a dataset and stay in sync with updates over time.
Whether the source is a cultural heritage collection, traffic sensor data, or a national data portal, the replication flow remains the same: fetch the most recent view, then follow links to receive incremental updates.
Only the vocabulary and application profile differ, which makes the replication pattern composable and reusable across domains.
LDES itself is also a good example of this separation of specs.
It consists of a vocabulary with application profiles for validating the pages, as well as the interaction patterns.
The spec itself is written from a consumer-perspective for that reason.
The application profile of LDES itself also reuses the TREE hypermedia vocabulary, making sure to reuse semantics where it makes sense.
Example: contract negotiation in the Dataspace Protocol
In dataspaces, data exchange usually requires a contract that specifies terms of use.
The Dataspace Protocol therefore defines an interaction pattern for contract negotiation.
It specifies the sequence of messages (offer, counter-offer, agreement) as well as their bindings to HTTP.
Participants in a dataspace can thus automate negotiations while still reusing existing vocabularies such as DCAT for dataset descriptions or ODRL for usage control policies.
This is a prime example of combining vocabularies, application profiles, and interaction patterns into a coherent whole.
Example: evaluating ODRL policies with N3 rules (FORCE)
ODRL gives us a shared language for usage control, but its evaluation semantics are still underspecified—different engines can interpret the same policy differently.
The Framework for ODRL Rule Compliance through Evaluation (FORCE) tackles this by defining a repeatable interaction pattern for policy evaluation and by shipping a tested evaluator plus a common report model.
Instead of having to hard-code the rules for evaluating such ODRL policies, they are described in Notation 3 (N3).
An engine runs those N3 rules to decide which permissions/obligations/prohibitions are active and returns a machine- and human-readable compliance report.
4. Implementation guides – agreeing on practice
Even with vocabularies, profiles, and interaction patterns, developers still need clear instructions to follow when implementing a specific use case.
That’s where implementation guides come in: they combine all artefacts into an end-to-end recipe, lowering the entry barrier for developers.
For example, in the SEMIC pilots on LDES, the implementation guides walk implementers through how to publish a dataset as a stream.
Instead of just defining vocabularies and patterns in the abstract, the guide gives concrete examples, step-by-step instructions, and reference implementations.
This made it possible for multiple domains to reuse the same replication pattern with only small adjustments.
Another strong example are the Once-Only Technical System (OOTS) specifications.
They provide the API descriptions for governmental procedures documented in the Single Digital Gateway Regulation (SDGR), such as how a citizen can change their address across borders.
The guides describe the flow end-to-end: which vocabularies to use (e.g. Core Person, Core Location), which application profiles to validate (e.g. CPSV-AP), and which interaction patterns to follow (e.g. verifiable credentials).
They could go further in this vision, but already show the power of an implementation guide as a binding document between law, policy, and technology.
Implementation guides complete the picture: they are the glue that ensures vocabularies, application profiles, and interaction patterns move from paper into running code.
Without them, interoperability risks staying theoretical. With them, it becomes practice.
P.S.
Seeing interoperability through these four artefacts helps avoid both extremes: the chaos of everyone doing their own thing, and the rigidity of forcing one grand standard.
Instead, we can identify what already exists at each level, reuse it, and only invent what’s missing.
This perspective also makes it easier to carry lessons across domains: a museum and a mobility operator may not share vocabularies, but they can certainly reuse the same interaction patterns or learn from each other’s implementation guides.
With this vision, I don’t believe we should build software that is domain-specific anymore.
No domain is so unique that it requires domain specific data pipelines.
There will always be opportunities to maximize the reuse of interaction patterns.
If a suitable one does not yet exist, we can define it in such a way that others can reuse it too.
That is how we move from isolated solutions to an ecosystem of reusable building blocks.
Well-intentioned initiatives to improve interoperability often run into the same problem: people have very different expectations of what “making services interoperable” actually means.
If the goal is simply to connect two systems, the task is relatively straightforward: implement the connection and hard-code the alignments. That’s been common practice for years, and even a solid business model for many integrators.
Today, generative AI can accelerate this process, but it will never make it truly scalable or reliably correct.
What we need instead is a higher level of ambition from data providers. Rather than assuming one-off manual integrations, providers can prepare their systems to be ready for integration with many others.
That’s the real quest toward interoperability, and it requires us to think in terms of different levels of ambition.
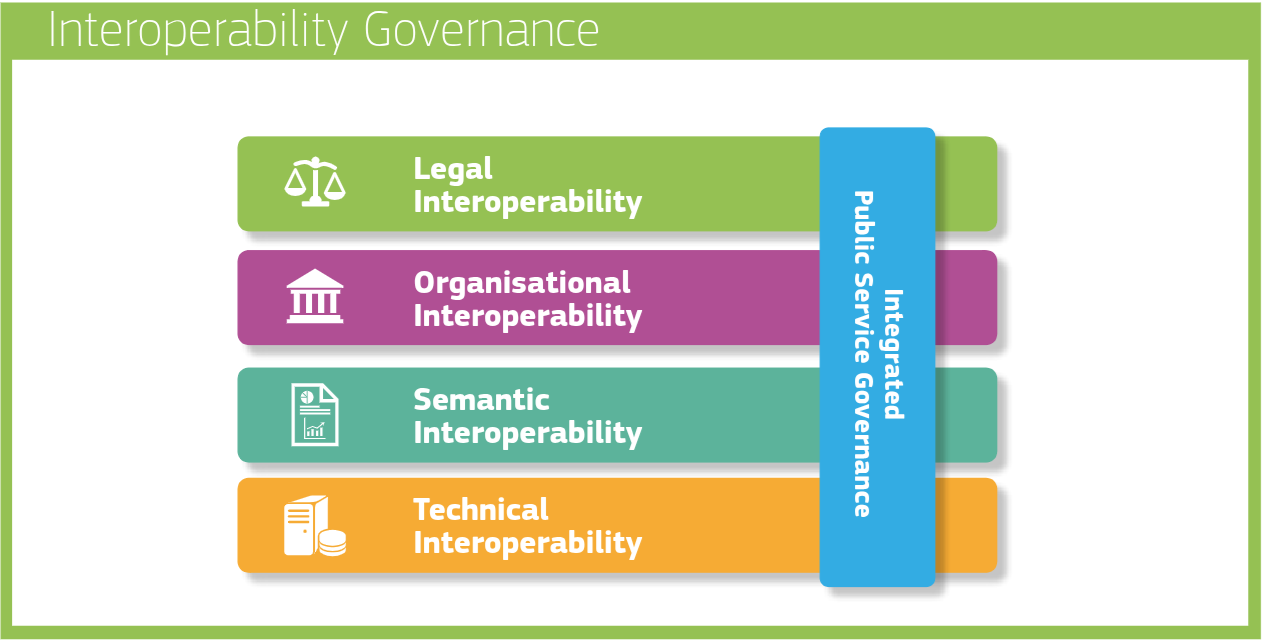
The four layers of interoperability in the European Interoperability Framework (EIF3, 2018)—legal, organizational, semantic, and technical—have been instrumental as a guiding mechanism.
It highlighted that interoperability is multi-faceted: it cannot be solved by software engineers alone.
No, it is to be solved in an integrated way, solving legal concerns with a legal team, solving organisational aspects using managers, solving technical hurdles with software engineers and making sure everyone has the same understanding for the terms used.
It introduced a new level of abstraction on top of how public administrations (who are the main target of the EIF) would look at making services run across the border of their own organization.
Interoperability becomes a governance concern you need to think about in advance instead of in hindsight.
Today this kind of layering has become well-understood.
However, not all interoperability challenges are now solved as we’re still taking the first steps into automating integrations, so they are cost-effective, reliable and scalable.
Next to these 4 layers, it’s time to take the next step in the complexities of interoperability governance and look at where we are today, where we should be heading tomorrow, and what our ambition will be in the long term.
A simple example of where we are today is the General Bikeshare Feed Specification (GBFS).
GBFS is a set of JSON schemas that makes it easier to discover and use shared mobility modes.
It is undeniable that this specification has had a positive effect on interoperability for apps to integrate the availability of shared mobility in a region.
However, the use cases on which interoperability was created remain limited to exactly those clients that specifically coded against the GBFS schemas.
There’s no reuse of semantics or specific interaction patterns that would help non-GBFS clients to still perform a task on the data, for example, to show it on a map, or to study the data as time series, or to show opening hours of specific services.
For that kind of cross-application reuse to become possible, we need to raise our ambitions.
Instead of each ecosystem inventing its own schema and API, we need a way to separate concerns more clearly: vocabularies that define shared terms, application profiles that define how those terms are used in a context, and interaction patterns that describe the workflows or exchanges between systems.
Add to that global identifiers that work across domains, and you get the foundation for reuse.
This is where interoperability stops being about “connecting system A to system B” and becomes about building common building blocks that any system can adopt.
One separation we know well in the world of Linked Data is between vocabularies and application profiles.
Vocabularies provide the global identifiers for domain specific terms.
Application profiles, on the other hand, assemble these terms from one or more vocabularies into a schema that a particular system or service expects.
For example, an application can use the property geo:asWKT from the OGC GeoSPARQL vocabulary to indicate that something has geospatial coordinates.
This pattern can then be reused by many other systems, even if they are working in different domains.
Not everyone will choose the same property to describe geospatial data, but that’s where alignments come in.
The global identifiers can be reused to provide a mapping between patterns.
A publication, that so far did not receive the attention it deserves, elaborating on this exact challenge, is “A Web API ecosystem through feature-based reuse” by prof. Michel Dumontier (known from his work on the FAIR principles) and prof. Ruben Verborgh.
APIs were originally intended to make automated connections easier, but in practice they often add complexity.
Each new API introduces its own contract, forcing developers to write a dedicated client, which leads to one client per API.
The paper argues for a shift to feature-based reuse: instead of treating every API as a silo, describe the features it provides and reuse features that others have already documented.
This way, a client only needs to implement a set of reusable features once, and it will work across multiple APIs.
It creates a looser, more flexible contract between APIs and clients, which is far more scalable than today’s approach.
Think of common API features such as pagination, filtering, synchronisation, or contract negotiation.
Instead of every ecosystem inventing its own way of doing these, we can standardise the patterns once and reuse them everywhere.
For example, the TREE hypermedia specification provides a reusable interaction pattern for pagination and subset discovery.
The SEMIC Linked Data Event Streams (LDES) specification builds on that to describe how a client can stay in sync with a changing dataset.
For contract negotiation, there is the Dataspace protocol that defines the interaction patterns as a state machine.
These are concrete, reusable building blocks that any domain can adopt, whether you’re in the domain of cultural heritage, traffic measurements, or building public services.
Domain specifications will this way become smaller, and be a combination of reusable components rather than a reinvention of the same patterns.
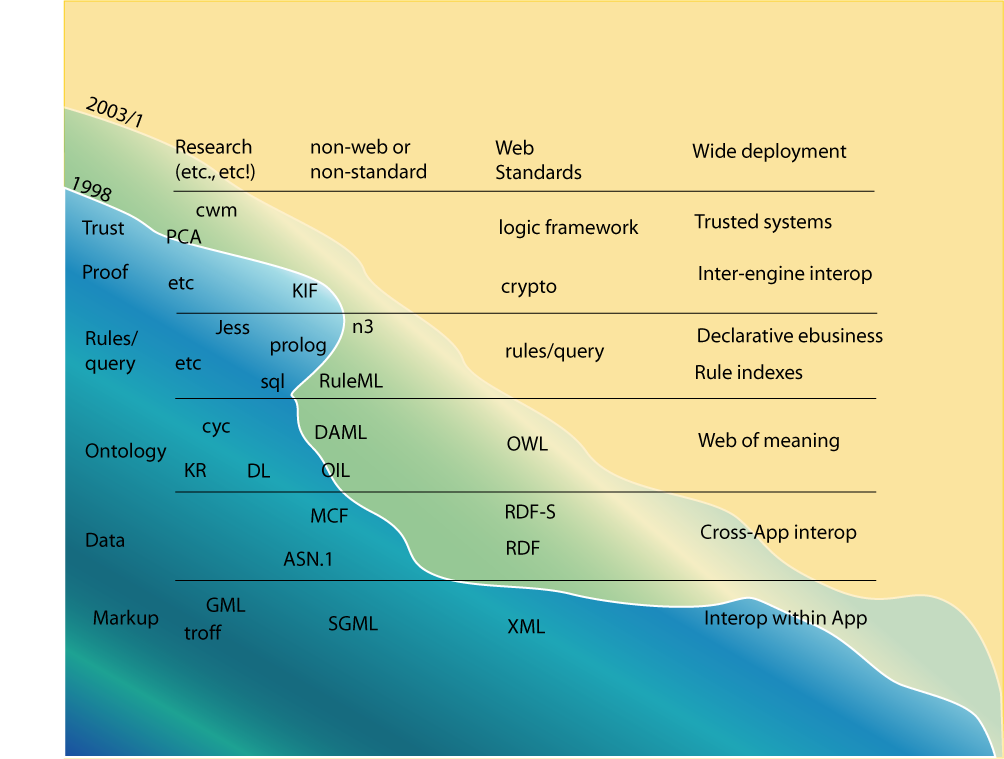
The Semantic Web Wave, as presented by prof. Tim Berners-Lee in a 2003 talk. Back then, XML would be for interoperability within an app ecosystem, RDF would be for cross-app interoperability, and logic would be for inter-engine interoperability.
In a 2003 presentation, prof. Tim Berners-Lee pitched the “Semantic Web Wave” (see above).
The idea was that there is a gradual approach to interoperability, where systems that already put in the effort to have interoperability within an ecosystem through tightly coupled specifications (interoperability within an app ecosystem), can evolve towards reusing Linked Data vocabularies and RDF serializations (cross-app interoperability).
Once they do, they can take the next step: documenting and sharing the logic so machines can interpret the data across implementations.
This last step goes beyond cross-app interoperability by insinuating that we won’t need to build any domain specific software anymore.
We will be able to ship a domain agnostic engine, together with the data.
The engine will be able to, through procedures and logical rules described in the data, understand how to interact with various systems for you.
The three ambition levels for interoperability
All good things come in threes.
Whenever positioning conceptual levels, I believe it is to convey where we are today, what we need to reach for in the short term and what the heading is in the long term.
Level 1 is what is already being adopted, level 2 is what is within reach, but often not yet available off the shelf, and level 3 should be a future outlook we can prepare for today.
Also the Semantic Web Wave by Tim Berners-Lee grasped the idea that you start with systems that only work within one tightly coupled ecosystem, then move towards shared vocabularies and patterns for interoperability cross ecosystems, and finally, you reach a point where systems can even share the logic for interpreting the data.
Let’s reiterate and modernise those levels for today’s use cases.
The three levels I propose follow the same idea and naming:
Level 1 — Interoperability within an app ecosystem
This is where most initiatives start. A group of actors in the same domain agrees on a format and a protocol. Developers can read the spec, build their implementation, and everything works smoothly — as long as you stay inside that ecosystem.
Think of the General Bikeshare Feed Specification (GBFS) for bike-sharing data, GeoJSON for geospatial points, MARC 21 in libraries, HL7 in healthcare, or NeTEx in public transport. Each technology has an undeniable impact within its own ecosystem, but if you want to use that data in another domain or platform, you’ll need to write extra code to bridge the gap.
Level 2 — Cross-ecosystem interoperability
Here, you go beyond your own domain and design with reuse in mind. Identifiers are global rather than local. Vocabularies, application profiles, and interaction patterns are separated so they can be mixed and matched.
This makes it possible for cultural heritage data to be aggregated with the same interaction patterns as a transport API, or for healthcare systems to reuse the same contract negotiation protocol as an industrial dataspace. It’s where RDF, SHACL, and hypermedia APIs start to appear as they make this kind of reuse possible.
Level 3 — Inter-engine interoperability
The final step is when you also include the logic in your specifications, so a machine can interpret, verify and interact with your data and systems without being built for your specific domain.
This is where AI and rule engines meet.
Today, most projects stop at Level 1 because it’s faster to implement and delivers value quickly.
Working our way upwards, we need to be able to show evidence that indeed, by making the abstractions necessary for Level 2 and even Level 3, will save a lot of work later.
The 3 ambition levels for interoperability summarized
P.S.
Are you interested in learning about interoperable dataspaces technology?
At this moment the registrations are open for the course on Linked Data, Solid and interoperable dataspaces. The course starts in September and runs until January.
Thank you Jos De Roo for telling me about this initial vision of Tim Berners-Lee at the coffee machine. I decided to adopt these original terms for interoperability ambitions as coined by him.
I am at this moment part of the expert team on the European Interoperability Framework (EIF). In this context I’m planning a couple of blog posts, for which this one is the first. These posts however do not reflect the position of the EIF.
]]>Pieter ColpaertEscaping the false dichotomy of API vs. data dump with Linked Data Event Streams2021-09-03T00:00:00+00:002021-09-03T00:00:00+00:00https://pietercolpaert.be/ldes/2021/09/03/ldes
Data publishers often face a familiar but painful choice: should they provide a full data dump or a querying API?
Each option comes with a hidden cost.
The data dump leads to replication hell—multiple copies scattered across consumers, each potentially outdated.
A querying API leads to maintenance hell—constant effort to keep endpoints up-to-date, scalable, and reliable.
With Linked Data Event Streams (LDES), we provide a way out...
Data publishers are too often asked to pick between two unsatisfying options.
The data dump looks harmless: publish a full export and let consumers do their thing.
In practice it creates a replication hell: multiple uncoordinated copies drift out of sync; consumers juggle deltas and snapshots; provenance cannot be traced; history gets lost in overwrites; and every “fresh” download quietly rebuilds the same indexes in a hundred places.
Take for example the address registry in Flanders for which data dumps are available.
Probably every municipality in Flanders takes a copy of this file for use cases such as autocompleting the street names for the forms they use everywhere.
When developers make such integrations, sychronization is an afterthough: this dataset doesn’t change that often anyway, right?
Think again: there are minor changes every day, with new addresses coming into play and old ones becoming “historized”.
When in 2016, 2019 and 2025, cities in Belgium decided to fuse, a lot of street names also needed to be renamed to avoid duplicate names.
Instead of this base registry being updated from the source, services started making the changes they needed manually in their local copies, leading to a replication hell.
On the other side sits the querying API.
It promises precision—ask only for what you need—while quietly enrolling the publisher in maintenance hell.
New use case? New endpoint.
New query language that became popular? Again yet another API to be provided.
The provider becomes an involuntary platform operator, while consumers still only have a limited processing possibility of the dataset as they can only query the API in the ways the data provider managed to set up.
Each endpoint that has been set up comes with its own maintenance cost.
After a while, when priorities shift or budgets shrink, it will have become impossible to turn off any of the existing APIs as there may still be an application that relies on it.
The budget that once was used for innovation and creating a better public service, is now being used for maintaining legacy APIs.
Take again the example of the address registry in Flanders for which next to data dumps, also a plethora of API products are available.
Specific functionalities that were once brought online, need to remain maintained: there may always be that one service that is still relying on this API.
Certainly for address registries, multiple functionalities of the dataset are expected, such as: finding the geolocation of an (or multiple) address(es), a geospatial interface to visualize the data, a historic view of what addresses existed in the past until today, an autocompletion interface for autocompleting streetnames, municipalities and addresses, a SPARQL, GQL and GraphQL API for graph-based access, a specific service that allows to calculate what addresses will be impacted by a road closure, etc.
It doesn’t matter how many APIs you have: it will never be sufficient—there’s always going to be that other person that needs a functionality that does not yet exist.
There are however other paths. Let’s start from the idea of taking full copies cfr. “dumps”, but let’s change the intent and the name. Let’s call it a stream. This way, it sets the expectation that developers of consumption pipelines will code for history and future: they will re-interpret what happened and with exactly the same code stay in sync with what will happen.
This is the mindset behind Linked Data Event Streams (LDES).
The ambition level (update: see a 2025 blog post) is to introduce semantic interoperability through Linked Data, and combine this idea with how developers interact with streams.
LDES publishes the dataset as an append-only sequence of immutable members with stable identifiers, so any party can replicate once and then follow updates.
Hence the straightforward name: the combination of having this ambition towards interoperability, and the ambition to always keep every copy up to date, becomes Linked Data + Event Streams: LDES in short.
The LDES logo
This shift unlocks governance opportunities.
With an authoritative event source online, the publisher can decide which higher-level interfaces to keep maintaining, and which to let the ecosystem carry.
A SPARQL endpoint, an OGC API, or a GraphQL service may be useful today and optional tomorrow.
If a GraphQL API stops aligning with the publisher’s priorities, the publisher can bring it offline, while the consumer that still needs it can spin up their own GraphQL server that replicates and synchronises from the event source, preserving functionality without forcing the publisher to keep every interface alive forever.
If you maintain a base registry or any dataset that changes over time, start by publishing the LDES at the event source. Everything else can—and should—derive from there.
With an authoritative event source online, the publisher can decide which higher-level interfaces to keep maintaining, and which to let the ecosystem carry.
For the technical details, see the LDES specification at https://w3id.org/ldes/specification.
Various implementations of clients and servers are available. In order to interact with the community, visit https://ldes.tech.
The talk at ENDORSE 2021
At ENDORSE 2021 there was a talk in which I explain the contents of this blog post in a talk:
P.S.
This post was planned to be publish in 2021, but remained in draft until 2025. I have only in 2025 taken the time to finalize it but have kept the initial planned publication time.
]]>Pieter ColpaertWhat we did in 2019 and will be doing in 20202019-12-31T00:00:00+00:002019-12-31T00:00:00+00:00https://pietercolpaert.be/research/2019/12/31/hindsight
It’s not research if you’re not learning in hindsight
I’m sure someone must have said it at some point
2019 was the second year I was a postdoctoral researcher at IDLab.
In this blog post I want to reflect on the research goals I set one year ago, but also what we are going to do in 2020.
It is curious to see that after all these years, I still underestimate certain steps, while I overestimate others.
Will we be able to the better at the end of 2020?
The blog post from one year ago is available here: our research in 2019”.
Our research focus was and will remain designing Public Web APIs.
Last year, I put forward our main research approach for read-only Web APIs as: “How do you fragments datasets bigger than 50kb?”.
Taking the fragmentation approach on a dataset helps to re-think and re-shape APIs for Open Datasets, yet putting forward an ideal size is certainly an oversimplification that we should not overuse.
The ideal size of a page depends on so many factors: update frequency of the data in the page, whatfor the data itself is used, how compact the data can be represented, how the data is requested by query engines, the compression rate, type of compression, cacheability, etc.
Nevertheless, for most use cases, 50kb after compression held as a good initial guess.
Thinking about dataset publishing as merely a fragmentation problem, helps a lot nevertheless.
I’ve started coining the idea of “the Web as a hard disk” to explain that no database expert in their right mind would suggest removing the page cache from an operating system.
It is this cache that is the enabler of the scalability of hard disk drives, powered by the locality of reference principle.
If we could use existing caches that are already in everyone’s pocket, HTTP browser caches, then we could make the web of data much more efficient as well.
The kind of fragmentation will lower the amount of fragments that need to be downloaded for a specific use case, but might not for the other.
We recommend to always work with real query logs from an existing API in order to prove a point.
Designing public Web APIs is not limited to just fragmenting.
Quickly you notice also other aspects come into play, that again make hosting more expensive:
supporting different serializations, allowing to request a version of the page from the archive, materializing data dumps for manual inspection, doing metadata well for both dataset discovery (dcat) as interface discovery (hydra) and provenance.
In non fragment-based interfaces we have however not even started to think about these problems.
Insights from 2019
In the Smart Flanders programme, we outlined technical principles that data publishers should adhere to.
The technical principles include adding a license to your dataset, enabling Cross Origin Resource Sharing, using JSON-LD over plain JSON, using the Flemish OSLO domain models, etc.
We have been working three full years on getting these principles accepted at local governments, working on how this translates into paragraphs to be put in tendering documents.
For the next years, it will be a challenge to translate these principles into architecture diagrams.
Different use cases were studied.
In last year’s blog post, we outlined 3 focus topics: time series, text search and geospatial search and specific ideas on how to tackle them.
The ideas we had on summarizing time series were too simplistic.
There is no silver bullet when it comes to summarizing time series, although a novel technique called Matrix Profile comes quite close.
We are now studying that approach for compatibility with Linked Data and hope to publish this in 2020.
For geospatial search, we are still in the process of developing different approaches.
R-tree and tiling have been studied and described using hypermedia.
In 2020 I hope we will be able to describe techniques like hexagonal tiling and geohashes too.
There might be an interesting overlap with text search there, as something that is geospatially contained within another region will have an id that has the id of the larger area as its prefix.
We abandoned the idea of hilbert indexes in hypermedia APIs however. They are an interesting idea for the back-end, but not for the hypermedia API itself.
We are working on publishing the results of benchmarks we ran for time series, geospatial search and autocompletion services. Keep an eye on our publications!
Goals in 2020
What would I love to look back on at the end of 2020? We are a team of computer scientists, so we should do two things well: write inspiring papers and deliver useful code.
I want to get the Tree Ontology presented at international conference and discuss its current design with experts in the field.
The current specification needs to be implemented in Comunica.
Linked Connections and Routable Tiles need to be updated to become interoperable with the Tree Ontology in a 2.0 version.
Planner.js will be further developed as a client for route planning purposes.
The planner will be extended with geospatial, time-based and full text search queries based on the Comunica implementation.
I want to work on developer enablement for autocompletion services. Today this relies on centralized services where you send your entire query to. This as such as a privacy nightmare, and will always operate with a closed world assumption trying to fit all the world’s knowledge on one machine. I want to build a Comunica based tool that enables developers to work with existing open datasets, without having to set up a server, and do autocompletion on the client-side without loss of user-perceived performance.
I will figure out how to integrate the Matrix Profile technique into a Web API specification for time series clients.
I want to dive deep into Read Write Data with SOLID (an ecosystem for personal data pods), implement a Mobility Profile into Planner.js, and figure out the parallels between SOLID shape descriptions and the Tree Ontology.
]]>Pieter ColpaertReal-time election results as Open Data2019-05-27T00:00:00+00:002019-05-27T00:00:00+00:00https://pietercolpaert.be/opinion/2019/05/27/elections
Is there a way to know the geospatial boundaries of the cantons?
Uhmm… Not sure…
The data of the 2019 elections in Belgium, as the counts were being registered, were Open Data.
Anyone was (and still is now) able to create their own view of the candidates per election, their preference votes, the parties and their votes...
Two weeks before the elections, we got confirmation we would receive the same data the media companies would receive about the election results.
We had to think and act quickly. What can we set up in what amount of time?
We decided to host a hackathon, or an electathon, how we decided to call it.
Thanks to the people of BeCentral, where Open Knowledge Belgium has its office, we quickly could reserve a meeting room on Saturday before the elections.
We set up a page at elections.openknowledge.be and we invited our network.
About 10 people showed up, with one common goal: we will build something that, if the data would not have been open, you would never be able to have such an overview.
Quickly, 3 main ideas came to exist:
A one vote one dot map, showing a dot in a color per vote in a canton. We did not prioritize this idea however: it was not straightforward to get a map of the boundaries of all cantons, and the demo code we were working with only worked for static data. It would technically become a challenge to visualize this as more votes came in, although we will keep this idea in mind for the next election. (idea by Leenke)
A deeplink to the personal achievements of one candidate. The page would be the ultimate vanity metric for politicians.
A 3D print of a vase that grows bigger when new results come in. The vase gets skewed in the direction of the winning party. We would then try to sell the vase for €30.000, which is the amount the media companies have to pay for the data if the open data was not there.
We decided to focus on the second idea and create an overview of the votes per candidate.
Jonathan created a best-effort API based on these files.
The API is publicly available without API keys, and has Cross Origin Resource Headers installed.
We also made sure the responses are compressed and the right caching headers were in place.
Everyone was now able to start coding upon this.
As an example, I coded up a quick codepen displaying the list of candidates per election.
This was quickly picked up on Twitter by Thib, who created a nice overview of who you can vote for, and the seat distribution in real-time.
Michiel is Open Knowledge’s knows all can do everything digital handyman.
He decided to implement the wireframes made by Leenke using React.
The app was ready just in time for the elections, although we had plenty of more ideas to go into the page.
See for example the personal result page of former minister of the Digital Agenda Alexander De Croo.
With more than 8000 unique visitors on Sunday of this webpage, we feel extremely proud that we have been able to pull this off.
Next elections we will go for more and better data, and more and better visualizations.
Playing with the data has given us a great insight in how Belgian elections actually work.
We had 6 elections with a total of 6927 candidates (I just checked with Michiel and he knew this number by heart by now).
For me as a Linked Open Data researcher, it became again painfully clear that we need better data management across silos in the government.
We stumbled upon a dead end when trying to find geo boundaries for Belgian voting cantons: that should have been a basic dataset.
We tried to find the logos of the parties on Wikidata.
However, not all parties had a wikidata page, and if they had one, not always was their image up to date.
Luckily you can edit wikidata yourself, but for this hackathon we quickly decided to make a file containing all logos and parties.
The I files in the election streams should become base registries, always available and not only available for the elections.
They should be available as Linked Open Data, so that all the identifiers for e.g., candidates, parties, lists, … could be shared among different datasets.
The R files could equally as well use the same domain model as the UK elections with the Election Ontology available at https://ukparliament.github.io/ontologies/election/election-ontology.html.
So many ideas to build a much more integrated data publishing strategy at the federal government.
Let’s hope there will be a minister of the digital agenda soon: we have plenty of things to tell!
]]>Pieter ColpaertThe next steps for Open Data Portals? Data recipes!2019-03-21T00:00:00+00:002019-03-21T00:00:00+00:00https://pietercolpaert.be/opinion/2019/03/21/data-portals-next-steps
My dataset is on the data portal, why isn’t it added in every route planner now?
A city official.
We have been building Open Data portals and Open Data standards (see DCAT) for a while now.
Yet, judging from the state of the art, still only humans get to understand what’s in an open data portal.
We somehow need better metadata, in order for machines to make sense out of the big pile of data gathered on an Open Data portal.
I believe the next challenges for Open Data portals are two-fold:
(i) making sure industry players adopt “data recipes” (discovery algorithms) for finding datasets for a specific feature; and
(ii) adding better metadata to existing datasets.
I believe the latter can be achieved by innovating the user interfaces for adding metadata to your dataset.
Stijn works for the city of Antwerp as a mobility specialist.
The problem he experiences is a text-book Open Data challenge:
How do I get a dataset about a new local policy adopted in third party end-user interfaces?
It is not an act of philanthropy that leads him to publishing this data, his data must be reused in order for his city to function properly.
It stresses the importance of having on the one hand intelligent bots that can integrate a dataset automatically,
but on the other hand also making sure the metadata is of a high quality, to assist machines looking for data.
From data catalogs to data recipes
Looking for a dataset is still a manual process.
I had to personally ask Stijn whether there is already an opendataset about this, who knew where the dataset could be retrieved.
It appeared to be in their geospatial dataset published (the metadata is so-far not yet integrated on the main open data portal) at portaal-stadantwerpen.opendata.arcgis.com.
This only left me to wonder: if I cannot find this dataset manually, how would a script from Google, TomTom or HERE be able to discover this dataset?
Instead of having human oriented full-text search forms in Open Data portals, we need to think about data recipes.
These are flow-charts or algorithms that a robot can execute in order to automatically discover certain datasets.
Such a recipe could look like this:
Study all next possible steps from the open data portal. For example, these “flow chart” blocks could be offered:
zoom in on a specific geographic region,
follow links to an overview of datasets that were added the latest,
read about the latest local council decisions (this is the first digital source that may be a trigger a change in route planning advice),
or follow links to datasets in certain themes such as “traffic rules”.
Follow the right links until a dataset of interest is found.
In the case of the Low Emission Zone (LEZ), it is a boundary shape. In the future we should make sure a robot can detect that “if you are inside this shape, some extra rules apply”. This way, any next set of extra rules, not only the LEZ, will become adopted automatically.
Every step in this recipe is close to how a human would discover a dataset, yet can be optimized for machines.
This needs some new alignments with data reusers.
On the one hand, companies such as TomTom, Google and HERE need to document what steps they take to understand data.
And in some way, Google already does this with the structured data testing tool or in this paper by Natasha Noy, Matthew Burgess and Natasha Noy from Google AI on creating a public dataset search engine.
This way, when you want to publish a new dataset, you can try to make it work with how machines already interpret your data.
On the other hand, you will have intended your data to be visited in certain ways.
Document your building blocks that you expose on your website.
At Informatie Vlaanderen, we put the first steps forward in this by creating a working group for a Generic Hypermedia API across Flanders.
Authoring environments for metadata
Problematic today is the fact that an Open Data portal is supposed to be delivered one company only.
A machine however does not care about back-end systems: links are followed seamlessly, regardless of what services are behind it.
The main page of opendata.antwerpen.be could be generated by the Drupal system,
the links to the geospatial search could link to an arcgis system,
while other links could be given to CKAN instances, The DataTank, OpenDataSoft, an IoT Data Broker, and so forth.
The important task for the people in charge of the Open Data portal in the city, is however to document the building blocks that are needed on every level, and expose these in machine readable hypermedia controls.
It is up to the company to make sure these building blocks that can be used in a data recipe by a client, are fully functional.
Yet, these building blocks today are invisible to the people who maintain the Open Data portal.
How can we make these more visible?
And can we come up with an authoring environment the automatically puts data currectly in this flowchart?
Could this authoring environment for metadata also automatically suggest other building blocks to be added to your dataset?
I think solving these questions will also automate a lot of steps for civil servants trying to publish data for maximum reuse.
In each case, Open Data is still a domain that still needs to mature a lot.
]]>Pieter ColpaertOur research in 2019 on automating data reuse2018-12-30T00:00:00+00:002018-12-30T00:00:00+00:00https://pietercolpaert.be/research/2018/12/30/automating-reuse
What’s the best Open Data interface for my dataset?
It depends.
2019 will be the second year I will be a post-doc at IDLab.
As long as I have research questions I am very curious to know the answer to, and as long as I am able to work with like-minded people across a wide range of organizations, this remains my dream job.
In this quick blog post I want to list the research questions we are working on.
On the one hand, out of transparency and being able to check myself at the end of 2019.
On the other, also because I hope other researchers also jump on this line of research and validate or refute one of these hypotheses in their own work, from their own perspective.
Feel free to reach out if you want to collaborate, or please let me know if you are working on something similar!
Our research topic is Open Data and Knowledge on Web-Scale.
If we want more people to publish their data, we need to work on:
Testing the scalability and cost-efficiency of Web APIs
When publishing data openly, we need to know how the web service will scale when more queries get asked. How it scales immediately also defines the cost-efficiency of such a web-service, as the better it scales, the more cost-effient a Web API will be.
Testing the user-perceived performance of Web APIs.
The real performance of a Web API is interesting, but what really matters is how users perceive the performance as an end-user. Maybe more data might be transferred, yet that may raise the probability that some data can come directly from cache and thus raises the user-perceived performance.
Qualitative research raising interoperability and simplifying reconciliation
We are mapping the hurdles in the creation process of a dataset and its relation to other datasets. E.g., what’s needed to make your dataset interoperable with others datasets?
Keeping this in mind, our main research question for 2019 becomes: “How do you fragments datasets bigger than 50kb?”
We are doing this both quantitatively, by measuring in lab and production environments what the effects are on cost-efficiency and user-perceived performance, as qualitatively, by reporting what worked and what didn’t with one of the many organization we collaborate with.
While many technical approaches can be thought of, still the organizational problem to put them into place are even more challenging.
Fragmenting datasets bigger than 50kb
When we want clients to solve questions automatically with Open Data, we on the one hand do not want them to have to download gigabytes of data dumps before being able to solve a question.
On the other hand, we also do not want servers to solve all questions for us, because then we did not solve the problem of Open Data we had in the first place (how would these servers have integrate all necessary data then?).
From the moment a dataset does not fit in one page any longer, we need to fragment this dataset.
We tested what would be the best page size of train departures in Linked Connections, and when compressing the HTTP responses, 50kb seems like a sweet spot.
As we did not yet test this in other domains yet, we generalize this number to all other datasets and use this as a good estimate.
So, from the moment we would publish a Linked Data document – being it in HTML, JSON-LD, TriG, or anything else – from the moment it exceeds 50kb, we should think about splitting the documents in fragments.
Depending on the feature that is needed and depending on which parameter the dataset needs to scale, the type of links (or hypermedia controls) and the type of fragmentation get decided.
One of the most straight-forward ways to fragment a dataset is using a paged collection.
A client could then download the first page of a paged collection, do joins and other operations with other datasets, and only when more data is needed, fetch the next page.
Yet, is that it? Can’t we do more to raise the user-perceived performance?
E.g., what if we tell the client that the paged collection is ordered in some way?
And if it’s ordered alphabetically, geographically or chronologically, can’t we speed up text search, geospatial lookups or time queries?
Full Text Search
Full Text Search is the engine behind many auto-completion forms.
An example of a UI picking a stop name from an autocomplete list. While the example might look straightforward, the actual implementation takes into account how many trains acquaint the station in order to order them by importance, and needs to take into account dataset-specific details, such as the fact that you might want to find “Brussels Central Station” when looking for the French “Bruxelles” or even “Bxl”. Or the fact that Saint Pancras might be shortened to St.-Pancras.
Today, full text search is taken for granted.
It is a heavily researched domain that tries to optimize search on machines with a fixed dataset.
It will be very hard for any other solution to beat the state of the art on cost-efficiency, user-perceived performance as well as the ease to set it up for your organization.
Yet... I want to try someting different.
Today on the Web there are two common ways to allow a data consumer to do text search in your database: or you allow them to download your entire data dump, or you allow them to send a partial string to the server and the server will give an answer that’s non negotiable.
Can’t we fragment a dataset by text strings, and ensure that a client can understand that it can now only download the right part of the dataset (~50kb) in order to solve the question on the client-side?
We are currently working on an implementation of a Patricia Trie, a Ternary search tree and a suffix array.
As we are setting up the experiments, we are extremely curious to see what the effect will be on the cost-efficiency and on the user-perceived performance.
If someone has a good dataset, with query logs of the past month we can reenact, we would be more than willing to peform our evaluation on your dataset!
Geospatial data
When we are talking database indices, geospatial ones are not to be forgotten.
In this field, strong standards are what organizationally makes it very complex to change anything.
E.g., the INSPIRE directive in Europe sets out principles that every member state needs to have a National Access Portal with all geospatial services.
This means, every geo-database in your administrations need to be able to handle any geospatial request possible at a certain time.
In order to start change in this area, again I want to research how much more cost-efficient it would become to do the geospatial querying on the client-side instead.
1. Geospatial Trees
Specialized data structures, such as an R-Tree, exist to store geospatial data.
A search algorithm can descend the tree to look for data that is in the vicinity of each other.
Geospatial queries are often about finding certain objects in a neighborhood. While in a traditional set-up, every of these map interactions would send a new query to the server, the client can already solve all other queries when the right data is available in the client’s HTTP cache. The green boxes are fragments that have been downloaded.
We have implemented this and have introduced the Tree Ontology to describe the hypermedia links between the pages.
The simplicity is striking: we only need to describe how a child relates to its parent document, and there are not that many relations we can imagine we need to implement.
The Tree Ontology in this way allows to expose any kind of search tree possible.
2. Tiling
It is strange that it’s common for an image mapping layer to implement tiles, and that there’s even a standard way to create “Slippy Maps” APIs (these allow you to pan around, while the client downloads the right tiles to fill the screen).
Yet, for data, tiling is not that common.
In the same way, we propose to tile geospatial information into tiles.
An example from our routable tiles project, where all roads are part of a tile. When you want your journey planner to route further, you can download more tiles.
3. Paged collection ordered by Hilbert index
A Hilbert curve orders 2 or 3 dimensional data on a 1 dimensional axis. This may allow us to go back to the easiest fragmentation strategy: 1 dimensional paging.
If there is a way to expose that a paged collection is ordered (I proposed this here to the Hydra community), then we could expose a Hilbert index for fragmenting the dataset in chunks of 50kb.
The client could then, using binary search, be able to select the right pages it needs to download.
While this will probably not beat the tiling approach, the creation of such a Hilbert index and merely ordering the collection in this way might be significantly more easy for a data publisher.
Time series
The tricky part with time series is that they keep increasing.
And once you have data with over a year of updates, it becomes ridiculous to suggest to a reuser that they have to download the entire year in order to calculate a simple average.
Therefore, we suggest also adding statistical summaries of your data across different fragments of observations.
We have started implementing and testing this as part of the Linked Times Series server project.
What else?
I’m intrigued whether the results on cost-effiency and performance are going to be worse, similar or better than the state of the art.
Yet, what if we have changing geospatial data that we want to do a full text search query on?
The really interesting happens when we combine multiple of these technologies.
In order to make sure all our building blocks are reusable, interchangeable and interoperable, we are building a highly module querying engine called Comunica.
Non research goals
I want to create a vivid open-source community with a route planner written in JavaScript
I want a dataset published of all the roads in the world, that can immediately be used by route planners.
2019 is also the last year of the current Smart Flanders programme.
Smart Flanders has probably been the main inspiration for these research questions.
The Open Data charter was launched and the first datasets were published compliant to the technical principles.
In 2019 I hope to push forward the technical readiness of local governments to implement Linked Open Data.
]]>Pieter ColpaertWe need better Open Data Interfaces2017-10-10T00:00:00+00:002017-10-10T00:00:00+00:00https://pietercolpaert.be/vacancies/2017/10/10/better-open-data-interfaces
Better?! Come on, you must be more precise with your feedback!
A scientist
The technology to publish data as broad as possible – Open Data – is slowly changing the world.
For example, it’s changing how we make decisions from gut-feeling to evidence-based.
It also makes our lives easier as route planning applications can consider more transport options than our brain, connected to the Web taking into account the latest real-time updates.
It is also the start of new business models, exploiting the growing mass of data that can be discovered online.
Every dataset, how small it may be, may contribute at some point to finding an answer to some question.
Yet, we have a big problem.
Almost nobody* is reusing the small datasets published on Open Data portals.
At least, if the data would indeed be useful, we should be able to notice evidence of data reuse in our daily applications.
Is this a huge fallacy for those who claim there is economic and societal value in their freshly published datasets?
For the years to come, Open Data researchers will need to prove that publishing data publicly is in the interest of both existing and new business models.
I accredit the lack of adoption today to a simple cost-benefit analysis: would you reuse a dataset when it costs you more to integrate it in your system than the benefits it would give to your end-users? I know I wouldn’t.
Now that I am a postdoctoral researcher, I am in charge of leading a small research team. For the next years, our new “Linked Open Data Interfaces” (LODI) team is going to research how to lower the cost for adoption.
I have already found funding to expand this team with junior researcher, and I am now looking for information/software engineers that would like to join.
* To be fair, there is some uptake, but not to the extent that data gets picked up automatically by any interface that could benefit from it. How can we advance the state of the art in data publishing, so Open Data really thrives?
What we do
We have a vision for a better world, where knowledge creates power for the many, not the few. If anyone can access public data, rather than a few with the deepest pockets, we create a more level playing field for building on top of the single and largest human knowledge base. You may recognize the slogan from the NGO Open Knowledge, with whom we work together in projects such as OASIS and open Summer of code.
We research how to create better Open Data interfaces.
We define “better” as how much easier it makes the lives of reusers.
Our job entails making sure the interfaces are more reliable (and thus more cost-efficient for the data publisher), interoperable, queryable and discoverable.
You can compare our Linked Open Data Interfaces team with a university hospital where a doctor does specialized consultation on the one hand, and ground breaking research on the other.
On the one hand, our inspiration for research comes from real experiences in the field.
We work with, among others, the Flemish government on projects to decide on the new open information architectures.
In bilateral projects, organizations can hire our team for short projects to publish data in better ways. But we are also involved in longer projects, where similar data interfaces need to be studied.
On the other hand, we do fundamental research. For example, with Linked Data Fragments we introduced a way to study the trade-offs on Linked Data Interfaces, we study what features of new technologies such as http/2 could be exploited for data publishing, or we are studying how to build a crawler that would be able to plan travels by public transit options world-wide.
You are joining team lodi (Linked Open Data Interfaces) at the Internet and Data Lab in Ghent: a team of 5 researchers that want to see a world where knowledge creates power for the many, not the few.
Your ambition is to become one of the main data architects within Flanders.
The first deadline is to send an e-mail to Pieter Colpaert with your CV and motivation letter before the 1st of September 2018.
We envision the first hire to start in October, but earlier or later is possible.
Other practicalities...
You have a masters degree and are experienced in computer science or engineering.
You are living in or willing to move to Belgium
You speak Dutch and live in Flanders. This is considered a big advantage, as many projects will be in collaboration with the Flemish government. But do apply if you are able to speak English as well! We will have other projects as well, and we are hiring 3 people in total.
The salary is fixed and depends on the years you have worked so far. We can make an estimation of a net salary if you contact us by mail.
The research you do can lead to a PhD (although this is not a requirement).
Things to read
We cannot wait to hear from you. If you however want to read up on our work, here’s a list of relevant links:
]]>Pieter ColpaertCC0 is the best open data license2017-02-23T00:00:00+00:002017-02-23T00:00:00+00:00https://pietercolpaert.be/open%20data/2017/02/23/cc0
Let’s crawl the Web! It will be fun!
Not your legal department
Data maintainers in and outside governmental institutions are in nature cautious with their datasets.
For open data, datasets are only worth as much as they get reused.
While data maintainers want to maximize this reuse, still, from the moment legal departments are involved, each organization seems to find their own reason to make reusing data unnecessarily complex.
In this opinion piece, I introduce the European Intellectual Property framework applied to Open Data publishing.
Everything is a trade-off: to what extent do we want to raise barriers in order to safeguard other interests other than maximizing uptake?
I propose to use Creative Commons Zero (CC0), which waives, to the extent possible, all intellectual property rights from the datasets.
Here’s why…
The foremost condition before a dataset can be called “open”, is that anyone is legally allowed to use it for any purpose.
A public license gives anyone more rights on this datasets.
Many exist and some organizations might even decide to create their own license.
Which license should you use for your data?
Let’s ask the Twitterverse first…
What’s the best license/waiver for #opendata? The goal should be to maximize the reuse of the dataset, such as with public transit schedules
Two thirds of the tweeps say CC0 is best suited for publishing Open Data.
Intellectual Property
As Intellectual Property Rights (ipr) legislation diverges across the world, we only checked the correctness of this chapter with European copyright legislation [4] in mind.
When a document is published on the Web, all rights are reserved by default until 70 years after the death of the last author.
When these documents are reused, modified and/or shared, the conscent of the copyright holder is needed.
This conscent can be given through a written statement, but can also be given to everyone at once through a public license.
In order to mark your own work for reuse, licenses, such as the Creative Commons licenses, exist, that can be reused without having to invent the same legal texts over and over again.
More information on the definition of Open Data maintained by Open Knowledge International is available at opendefinition.org [7]
Data can only be called Open Data, when anyone is able to freely access, use, modify, and share for any purpose (subject, at most, to requirements that preserve provenance and openness).
Some data are by definition open, as they there is no Intellectual Property Rights (ipr) applicable.
When there is some kind of ipr on the data, an open license is required.
This license must allow the right to reuse, modify and share without exception.
From the moment there are custom restrictions (other than preserving provenance or openness), it cannot be called “open”.
Uncertainty
For this text, I’ve consulted The Jurists, who were so kind to give me their opinion on this matter.
While the examples given here may sound straightforward, these two ipr frameworks are the source of much uncertainty.
Take for example the case of the Diary of Anne Frank [8], for which it is unclear who last wrote the book.
While some argue it is in the public domain, the organization now holding the copyright states the father did editorial changes, and the father of Anne Frank died much later.
For the reason of avoiding complexity when reusing documents – and not only for this reason – it is desired that the authoritative source can verify the document’s provenance or authors at all time, and a license our waiver are included in the dataset’s metadata.
When this book would be processed for the data facts that are stored within this book, what happens to copyright?
Rulings in court help us to understand how this should be interpreted.
A case in the online newspaper sector, Public Relations Consultants Association Ltd vs. The Newspaper Licensing Agency Ltd [9] in the UK in 2014, interpreted the 5th article of the European directive on copyright in the way that a copy that happens for the purpose of text and data mining is incidental, and no conscent should be granted for this type of copies.
Next, considering the database rights, it is unclear what a substantial investment is, regarding the data contained within these documents.
One of the most prominent arrests for the area of Open (Transport) Data, was the ruling of the British Horseracing Board Ltd and Others vs. William Hill Organization Ltd [10], which stated that the results of horse races collected by a third party was not infringing the database rights of the horse race organizer.
The horse race organizer does not invest in the database, as the results are a natural consequence of holding horse races.
In the same way, we argue the railway schedules of a public transport agency are not protected by database law either, as a public transport agency does not have to invest in maintaining this dataset.
These interpretations of copyright and sui generis are also confirmed by a study of EU Commission on intellectual property rights for text mining and data analysis [6].
Which licenses to use?
When I’m talking about Open Data, I’m talking about data for which the reuse should be maximized.
And it’s my responsibility to make sure that my data interface can handle peaks of high demand.
I want user agents – or crawlers, bots and scrapers – of any kind to retrieve my data and process it.
Talking about copyright within this Web context becomes difficult as the value of the container the data is contained in is marginal to the data itself.
Almost all “copies” on the Web are merely incidental, thanks to the great caching mechanism behind the HTTP protocol.
It is thus questionable how applicable existing copyright legislation is on the documents when publishing data in a technically interoperable way on the Web.
From all rights reserved to public domain, I believe the added complexities for reusers are not worth the added value for data owners.
When we want the data facts itself to be reused as broadly as possible, we do not want to make it unnecessarily complex for data consumers.
The document that ships our data is automatically copyrighted, so we want to waive this copyright.
Furthermore, when we would be able to protect our data through sui generis, it should be clear we don’t want to do that.
For this purpose, the Creative Commons Zero waiver is the best “license” to use:
it waives, to the extent possible, your IPR from a document and it indicates that you do not have the intention to enforce any remaining intellectual property rights that would exist.
Attribution
Using an Attribution license still complies to the Open Definition.
Requiring that you mention the source of the dataset in each application that reuses my data, still complies to the Open Definition.
There is no need to argue with anyone that uses for example the CC BY license: you will only have the annoying obligation that you have to mention the name in a user interface.
This is useful for datasets which are closely tied to their document or database:
when for example reusing and republishing a spreadsheet, I can understand you will want that someone attributes you for created that spreadsheet.
However, for data on the Web, the borders between data silos are fading and queries are evaluated over plenty of databases.
Then requiring that each dataset is mentioned in the user interface is just annoying end-users.
It is however important that the provenance of every kind of question can be looked up.
When I see an answer on my screen, I would love to have an “Oh Yeah?” button (coined by Tim Berners-Lee) for, which explains how the question was answered and links me to the original sources.
I however do not believe this should be a legal requirement.
It is just a design principle I believe future app developers should adopt.
Even if it would then not be visible in an end-user app, your browser could still expose this kind of provenance information using e.g., a browser extension.
Although CC0 doesn’t legally require users of the data to cite the source, it does not affect the ethical norms for attribution in scientific and research communities.
Using a Share Alike license still complies to the Open Definition.
The share alike requirement, as the name implies, requires that when reusing a document, you share the resulting document under the same license.
I like the idea for “viral” licenses and the fact that all results from this document will now also become open data.
However, what does it mean exactly for an answer that is generated on the basis of 2 or more datasets?
And what if one of these datasets would be a private dataset (e.g., a user profile)?
It thus would make it even more unnecessarily complex to reuse data, while the goal was to maximize the reuse of our dataset.
Non commercial
Using a Non Commercial license does not comply to the Open Definition.
When you want to reuse datasets sustainably, you are going to need a business model, and thus it is a condradictio in terminis that you may be able to reuse data in a non commercial way.
Noël Van Herreweghe, the programme manager for Open Data in Flanders, asked this question on Twitter. As an avid open transport data researcher, I felt like this question was in dire need of a response.
Data services are not data publishing
In “Open Licensing of Real-Time Public Sector Transit Data” [1], Scassa and Diebel argue that the license on top of real-time open data needs to be different than on top of a dataset.
While I agree with their analysis that a data service needs different terms than data publishing (read “I do not want your Open Data API, I’d rather scrape your website”), they do not make the distinction.
Real-time public transport data, as with Linked Connections or gtfs-rt means that next to the data dump, a file is put online, which is updated each (for example) 30 seconds with the latest delay and cancellations information.
Still, this is just a file that can be delivered quickly to an end-user, and falls under the same terms as a data dump.
A route planning API however, something I find a very bad idea for an Open Data strategy (read “Route Planning services should not be built by governmental organizations”), indeed needs its own kind of terms.
Even more: a route planning API should not even be publicly available.
Concluding that there are various implications with real-time open data for smart cities in general is due to the fact that they looked at the wrong kind of publishing interfaces.
I do not want anyone to pretend they’re me
I got a question from a colleague asking what license he should put on his open dataset of his titles and abstracts of his papers in.
When I told him that he should put it in CC0, he asked whether anyone would then be able to take his abstract and republish it as if it were theirs.
On the public forum of the Open Data Institute of Queensland, when the question was asked whether to use CC0 or CC-BY, CC-BY was recommended.
The claim is made that CC0 brings more legal uncertainty than CC BY.
Also across different European member states, legislation indeed still varies to what extent you can waive your rights on top of data.
While ODI Queensland argues that this legal uncertainty of the exact interpretation is bad, a lot depends on intention as well.
Documenting your dataset with a CC0 waiver indicates to potential reusers that the data owners will not enforce unwaived rights.
This intention is clear with CC0, while it is not with CC BY, where “how to attribute” diverges across different datasets.
As keeping the provenance of your data when answering questions is an important work ethic of a data scientist anyway, I would still accept CC BY as a standard license for Open Data.
With CC0, data owners also waiving their reponsibility?
I got an interesting reaction on the twitter poll saying that waiving the legal obligation to keep your data up to date is not a good practise for Open Data.
@pietercolpaert Creative Commons 0 is not a good license for open data, implies you're abandoning your rights (inc. promise of updates).
Is indeed CC0 promoting sharing data without having to keep it up to date any longer?
A license or a waiver that states that a dataset comes without waranty, does not give a wildcard for being able to put “alternative facts” in datasets.
E.g., when a document you publish is the authoritative source for something, you are responsible, as part of your job description, to correctly represent the real world.
Responsibility for a dataset should not be something that depends on an open data license.
The metadata of the file should sketch the context in which the data is being published.
Is it a one time file that is published as part of an experiment to open up the first datasets?
Or is this an authoritative source than can be relied upon by various Web agents?
Our legal department wants us to draft our own license
Machines already know how to interpret links to licenses like the CC0 or CC-BY license.
If you create your own license, how open it may be, this license also needs again to be understood by user agents.
The effort that is put in to create a new license, could be better used to annotate your dataset better, so that user agents can automatically be guided to execute the desired behavior.
Conclusion
Copyright legislation varies slightly across different countries world-wide.
The biggest building blocks we do share and we can assume copyright is only applicable on documents, not on the data facts itself.
In Europe, when you extract data from documents, this is regarded as an “incidental” copy for which the copyright legislation should not be applied.
For databases, a “sui generis” protection law exists.
This law dictates that you can protect your data when you invested substantially in its creation.
For data that are a natural consequence of what you are paid for to do (e.g., lottery results or train schedules), this law does not apply.
As a data publisher, you may try to enforce an attribution or share alike license, but on top of data, this becomes really hard to enforce.
If you are not going to put in the effort to enforce attribution, which is anyway part of the work ethic of any data scientist, why would you put in the legal obligation anyway?
It would only make it more vague what the conditions are to reuse your data, and for Open Data, your foremost goal is to maximize its reuse anyway.
Some datasets are made available on the Web using a data service instead of documents. I agree that this needs different terms and conditions to be accepted and maybe even needs authentication before you are allowed to access the service. This is not a proper way to publish data on the Web though.
While I would have no big problems with an attribution license on top of the dataset — it’s still open data — I overall recommend the CC0 waiver for datasets published in documents.
References
[1]
Scassa, Teresa and Diebel, Alexandra, Open or Closed? Open Licensing of Real-Time Public Sector Transit Data (December 19, 2016). (2016) Journal of e-Democracy 8:2, 1-19; Ottawa Faculty of Law Working Paper No. 2017-02.